Anthropic shipped Claude Opus 4.8 today. Same price as 4.7. Fast mode is three times cheaper than it used to be. And there is a new Claude Code setting called ultracode that is worth paying attention to.
Here is the short version of what landed, what is real, and what I think about it.
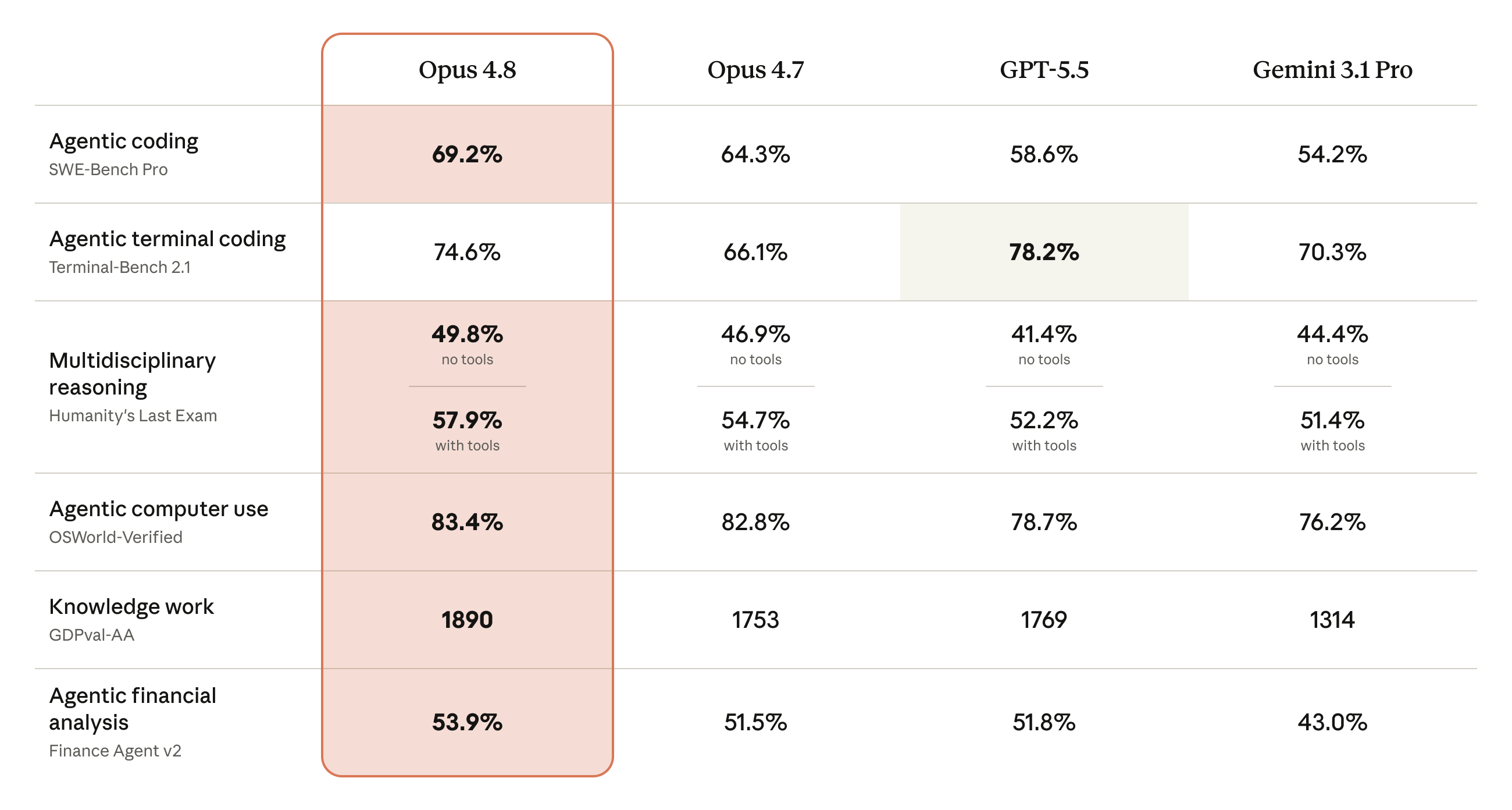
What Opus 4.8 Actually Is
It is a step up from Opus 4.7, not a generational jump. Anthropic itself calls it a modest but tangible improvement. 69.2 on SWE-Bench Pro, 83.4 on OSWorld-Verified, 1890 on GDPval-AA. Leads on five of six benchmarks Anthropic published. GPT-5.5 still wins on Terminal-Bench 2.1 at 78.2.
Pricing did not move. Five bucks per million input tokens, twenty five per million output. Fast mode runs at 2.5x speed and is now ten and fifty, which is a real cut from where fast mode used to sit.
My take. The interesting story is not the leaderboard. It is that Anthropic shipped a real upgrade four weeks after the rough 4.7 launch in April, and they did it without raising the price. That tells you something about the cadence they are trying to set, and frankly about the pressure they are under with OpenAI breathing down their neck.
Ultracode Is Not Just a New Effort Level
This part is getting reported wrong. Ultracode is not low, medium, high, extra, max plus one more notch. It is a Claude Code specific setting that lives in the effort menu and does two things at the same time. It pins effort to xhigh, and it tells Claude to decide on its own when to spin up a dynamic workflow.
Dynamic workflows are the other big shoe. Claude writes its own orchestration script, fans the job out across tens to hundreds of parallel subagents, runs adversarial agents to try to refute the result, and only hands you back the answer once things converge. The Bun rewrite Anthropic dropped as an example was 750,000 lines of Rust ported from Zig in eleven days, with 99.8 percent of the test suite passing.
My take. Ultracode is a quiet shift. The mental model used to be you pick the model and you pick the effort. Now you flip a switch and Claude decides whether your task deserves one shot, deeper thinking, or a hundred agents grinding for an hour. The trade is real. You are giving up some control and you are paying meaningfully more tokens when the workflow triggers. For codebase-wide bug hunts and migrations that is a fair deal. For a fifteen line bug fix it is overkill. Use it where the scope justifies it.
The Honesty Claim That Actually Caught My Eye
Anthropic says Opus 4.8 is about four times less likely than 4.7 to let flaws in its own code pass without flagging them. Their alignment team also said the model hits new highs on supporting user autonomy and acting in the user's best interest, with misaligned behavior rates similar to their best aligned model, Mythos Preview.
These are Anthropic's own numbers on Anthropic's own evals. Take the size of the multiplier with a grain of salt.
My take. The direction matters even if the exact number does not. The single most annoying thing about coding agents in 2025 and early 2026 was them confidently telling you the job was done while the tests were on fire. If 4.8 actually does flag uncertainty more often instead of plowing ahead with a smile, that changes how much real work you can offload. It is the difference between a junior who knows what they do not know and a junior who does not. I would rather have the former running unattended overnight.
Mythos Is Looming
Buried at the end of the announcement is a teaser for Mythos class models. Higher intelligence than Opus. Currently in Project Glasswing, used by a small number of orgs for cybersecurity work, gated behind safeguards that Anthropic says are still being built. They expect to release more broadly in the coming weeks.
My take. Anthropic just hit a $900B valuation on Tuesday, then dropped a real model upgrade two days later, then quietly waved at the next class of models on the way. That is a pretty clear flex. Whether Mythos actually ships in weeks or quarters is a different question, but the message to OpenAI and Google is that the gap they think they have is smaller than they think it is.
If you build with Claude Code, turn ultracode on for one task this week and see how it behaves. That is the single best way to feel what changed. Everything else is just numbers on a chart.